
Media
Can you use AI art to generate digital media creative?
While ChatGPT is still making waves, it’s AI art that has really taken off in 2023, with several tools released and readily accessible to the public.
For the first time, those with no natural ability can create art from scratch, with the limiting factor being how you can curate keywords and tweak settings, rather than how well you, as an individual, can draw, illustrate or paint.
The three main players in the AI art space are currently:
Each of these work slightly differently, have different levels of customisations and give markedly different output (Midjourney in particular has a very recognisable style). All three, however, share the common theme of taking natural language prompts and outputting images.
As an example of what can be done, the The New York Times ran this article on how an image generated via Midjourney won a digital art competition:

Given what these tools can do, there is no surprise that there is a backlash from digital artists, with a number of lawsuits in the US. Looking at what you can generate in seconds from these AI art tools, compared to the work of digital artists, something does feel inherently off:

Left: “Dragon Cage” by Greg Rutkowski (cropped), right: StableAI with “Greg Rutkowski” as a keyword
However, claims that these are “collages” or “averages” of existing artwork are inaccurate. These tools are trained on libraries containing billions of images, which are converted into mathematical representations of various concepts, rather than simply storing and blending images together.
There are lengthy arguments to be had on the ethics of AI art and the grey area it sits within, not to mention the impact it will have on artists and the art industry as a whole.
So, with the ability to create art with just a selection of keywords, can we use this to generate digital media creative? Let’s find out.
The brief and getting started
My brief is for a fictional client (a retirement home developer with zero assets or imagery), and the goal is to create a digital ad in multiple sizes as proof of concept for a new development they are selling.
Ahead of testing, an important consideration is that AI art models don’t work well with text – the meaning and nuance of each letter and the order they are in adds a whole further level of complexity. Given this, I will add both branding and a call-to-action by hand, outside of the Stable Diffusion platform.
To start, I used Stable Diffusion Web UI from github, running v1.4 of the Stable Diffusion model.
After installing this and the required dependencies, I‘m ready to begin.
Keywords and image generation
Sticking with mostly default settings, I first selected my keywords.
For inspiration, there are sites such as Stable Diffusion V1 Modifier Studies which can show you the sort of output to expect from each prompt, but you can also just play around with what you get back.
I ended up going for a fairly simple prompt, with some general “quality” keywords added in: retirement home, elegant, detailed, award winning, masterpiece

After the first few generations, I found the imagery was more reflective of American properties, so I added “UK” to my keywords which returned some more appropriate results.

I did notice while experimenting that the tool seemed to work better when my keywords were less specific, and adding more descriptive words (i.e. colours, framing etc..) led to a less visually appealing result.
After several rounds, the two images above were the strongest contenders, and I settled on the image with what looked like terraced housing. However there were a few visual inconsistencies I wanted to fix (for example, the grass and paving merged together at the front of the image).
To do this, I used a feature called “Inpainting”. This lets me take an image, create a mask (the area I want to work with) and regenerate that portion of the image.
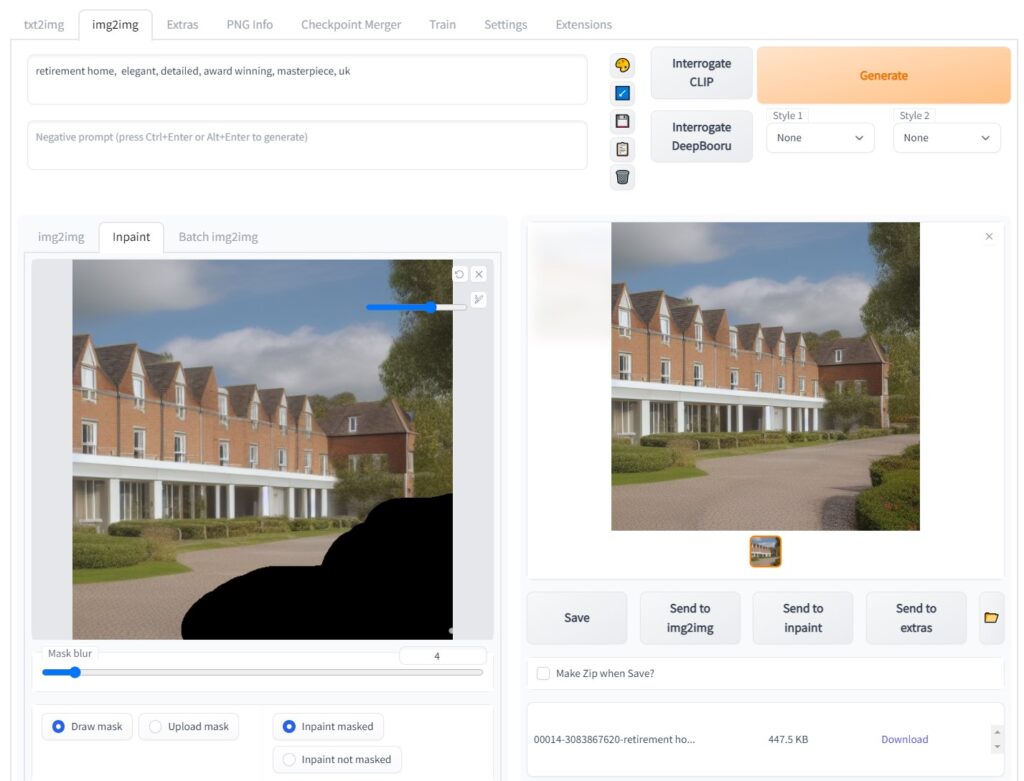
This meant I was able to keep the broad theme, but revise some of the details. Here are a few examples of repainting the image with this mask in place across the bottom right of the image:

After settling on this, I also decided to mask up and adjust the roof as well.

Whilst there are still a few issues that could be resolved with time and/or manual editing, I felt the final image generated was good enough for now.
Upscaling the output
Stable Diffusion is trained on fairly small image sizes (512×512) and whilst it can output larger images, the quality can sharply decrease.
This can, however, be offset by the use of further AI-powered tools, such as AI Gigapixel or Cupscale for example.
There is a tradeoff here in the detail – the upscaling process amplifies the small visual discrepancies in the image that are harder to detect when the image is softer in its original 512×512 format.

In this example, done via Cupscale, you can see elements such as the foreground bush on the right looks a lot better, however it’s clearer that there are significant issues with the roof towards the back.
Adding branding and call-to-actions
As mentioned, Stable Diffusion doesn’t handle text with images. To turn this image into an actual ad, I manually added a very simple overlay for my fabricated client, “housingbase”.

Creating ad variants
So, I have one format, but for use in media we generally need a mix of assets in a variety of sizes, to maximise the ad inventory we are eligible for.
Off the bat, this represents an issue – the Stable Diffusion model is trained on 1×1 images. Whilst I could simply crop my upscaled image into various sizes, this wouldn’t look great and I wanted to find a native solution.
Inpainting offered little success in creating a horizontal or vertical format from my existing images:
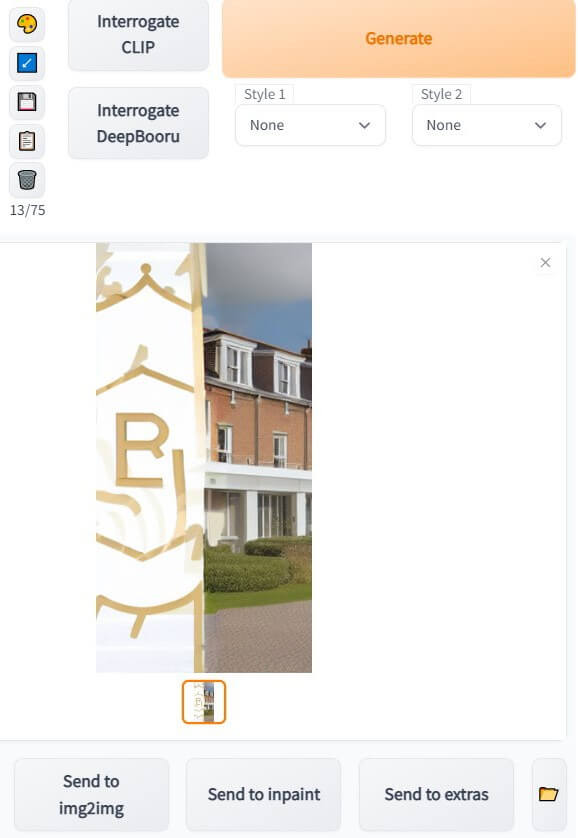
Given that, I tried using img2img within the platform – this takes an existing image, and uses it as a prompt for a new image.
I set the source as my 1×1 ad and the output as horizontal/vertical format. I also included the specific seed (the randomised “master key”) of my original image to try and keep the look and feel similar.
Whilst this worked, the results were not great. Overall the quality was much lower, and would need several rounds of inpainting or manual editing.

Wrapping up
So in summary, is it worth it? Whilst I was able to get something out at the end, the result is average (at best) and took a fair bit of work – not to mention needing to add the branding and call-to-action manually.
One takeaway from experimenting was that being too prescriptive with keywords was resulting in less visually appealing results. This of course goes counter to what we want from both the branding side (high production value imagery without visual distortions and in line with a brand style) and from an ad execution side (multiple formats all of which look good and are suitable for the placement).
One area I’ve not touched on is creative concepting and the “big idea”, which can account for the majority of the success (or lack thereof) you get from your creative. My ad is about as generic as they come, as I try to visualise what the “client” is offering, with no particular through line or idea. It does feel as though we are still quite far away from a time where AI can come up with truly inspired ad concepts which will cut through the noise.
Looking in the market there are already several tools for ‘AI generated creative’, however many of these take a different approach, combining pre-existing images and text assets in multiple formats. Will tools like these adapt and start to use AI art to further enhance (or even generate) images, using a model built specifically from ad creative?
Whilst the ability to generate completely new art and images through text prompts alone is huge, there are significant barriers to outsourcing digital creative to these tools. Even so, there are still a lot of use cases for tools like Stable Diffusion, such as brainstorming new ideas or quickly mocking up a proof of concept to be fleshed out.